
您是否正在尋找一種快速在英特爾平臺上執行神經網路推斷的方法?那麼 OpenVINO 工具包正是您需要的。它提供了大量的最佳化,允許在 CPU、VPU、整合顯示卡和 FPGA 上進行閃電般的快速推斷。
在之前的 帖子 中,我們瞭解瞭如何在 OpenVINO 環境中準備和執行 DNN 模型。今天您將瞭解有關 DNN 模型最佳化技術的更多資訊。
我們將涵蓋以下主題
- 先決條件
- 模型最佳化器
- 訓練後最佳化工具
- 基準測試工具
- 總結和結論
1. 先決條件
在我們開始之前,請確保您已安裝最新版本的 OpenVINO 工具包。為此,您應該使用官方安裝說明:這些說明適用於大多數常用平臺(Linux、MacOS、Windows)。對於本示例,我們將使用 Ubuntu 18.04。
請確保 OpenVINO 環境已正確初始化。您可以使用以下命令手動執行此操作
source <OPENVINO_INSTALL_DIR>/bin/setupvars.sh
或者,您可以將此命令新增到 bash 初始化指令碼
`~/.bashrc` config
因此,每次開啟新終端視窗時,環境都會被初始化。
讓我們下載並準備模型以進行我們的實驗。我們將使用 BlazeFace 和 FaceMesh 的 PyTorch 實現(分別來自 這裡 和 這裡),這些模型已在之前的 帖子 中轉換為 ONNX 格式。但是,OpenVINO 允許我們使用來自其他流行框架(如 TensorFlow、Caffe 或 MxNet)的各種模型。
mkdir -p ~/openvino_optimization/models cd ~/openvino_optimization/models wget link_to_GoogleDrive_blazeface.onnx wget link_to_GoogleDrive_facemesh.onnx
2. 模型最佳化器
通常,經過訓練的 DNN(以及我們之前下載的模型)預設情況下未針對推斷進行最佳化。OpenVINO 工具包提供 模型最佳化器 - 一個使用靜態模型分析來最佳化目標裝置上推斷的模型的工具。具體來說,它將一些連續操作融合在一起,以獲得更好的效能。
2.1 安裝和配置
模型最佳化器作為 OpenVINO 工具包的一部分部署。它的安裝和配置是工具包安裝說明的一部分,要配置它,我們只需執行
cd <OPENVINO_INSTALL_DIR>/deployment_tools/model_optimizer/install_prerequisites sudo ./install_prerequisites.sh
請注意,這將全域性安裝先決條件。為了保持系統清潔,您可能希望在專用環境中初始化它
virtualenv --system-site-packages -p python3 ./venv source ./venv/bin/activate ./install_prerequisites.sh
2.2 將模型轉換為中間表示
為了執行模型最佳化器,我們應該使用位於 <OPENVINO_INSTALL_DIR>/deployment_tools/model_optimizer 目錄中的 mo.py 指令碼。最簡單的方法是將模型檔案作為輸入提供
python3 mo.py --input_model INPUT_MODEL
模型最佳化器是高度可配置的。有一組可用於調整轉換過程的引數。模型最佳化器還允許將輸入預處理階段合併到生成的模型中。
- –input_shape: 應饋送到模型的輸入節點的輸入形狀。
- –scale: 來自原始網路輸入的所有輸入值將除以該值。
- — mean_values: 用於輸入影像的每個通道均值。
- –scale_values: 用於輸入影像的每個通道縮放值。
- –data_type: 所有中間張量和權重的型別 (FP16、FP32)。
讓我們最佳化我們準備好的 ONNX 模型。
mo.py --input_model ~/openvino_optimization/models/blazeface.onnx --model_name blazeface_fp32 mo.py --input_model ~/openvino_optimization/models/facemesh.onnx --model_name facemesh_fp32
最佳化結果是為每個模型建立了一個 `.xml` 檔案 - 它包含模型架構描述。我們還建立了包含模型權重和偏差的 `.bin` 檔案。我們可以將這些檔案載入到 OpenVINO 推斷引擎中以進行最佳化推斷。
在本示例中,我們的模型在內部具有全精度浮點運算 - 以 FP32 格式。但是,某些裝置(如基於英特爾® Movidius™ Myriad™ X VPU 的裝置)僅支援 FP16。 這允許在諸如 英特爾神經計算棒 2 或 OpenCV AI Kit 這樣的裝置上進行高效的神經網路推斷。 要將模型部署到類似的邊緣裝置,請將其轉換為 FP16 格式。
mo.py --data_type FP16 --input_model ~/openvino_optimization/models/blazeface.onnx --model_name blazeface_fp16 mo.py --data_type FP16 --input_model ~/openvino_optimization/models/facemesh.onnx --model_name facemesh_fp16
FP 16 或“半精度計算”具有較小的值範圍。但是,在許多工中,範圍可能足夠好,推斷質量將保持不變。並且模型消耗的記憶體更少。例如,在我們的案例中,FP16 模型權重檔案的大小是 FP32 模型權重檔案大小的一半。
半精度模型也可能提供更好的效能。但值得注意的是,並非所有硬體架構都支援 FP16。
3. 訓練後最佳化工具
OpenVINO 工具包中部署的另一個最佳化工具是訓練後最佳化工具 (POT)。它專為不需要重新訓練模型的先進深度學習模型最佳化技術而設計。
3.1 安裝和配置
讓我們安裝 POT。
cd <OPENVINO_INSTALL_DIR>/deployment_tools/tools/post_training_optimization_toolkit python3 setup.py install
這將在 python 環境中部署該工具,並且該工具將透過 pot 別名可用。要驗證安裝是否成功,您可以執行 pot -h
3.2 在 OpenVino 中進行低精度量化和推斷
POT 提供的主要壓縮和加速技術是 **統一模型量化**。 它允許使用低精度定點數字(例如,INT8)來近似原始全精度浮點 (FP32) 網路權重。
量化分兩個階段進行
1. **模型量化**。在一些網路層之前添加了特殊的 FakeQuantize 操作以建立量化張量。此階段的輸出是量化模型。量化模型的精度保持不變,量化張量儲存在原始精度範圍內 (FP32)。
2. **低精度推斷**。此階段由 OpenVINO 推斷引擎使用的 CPU 外掛 執行。此外掛更新 FakeQuantize 層以使用低精度範圍內的量化輸出張量。它還添加了去量化層以彌補更新。去量化層儘可能地推送到多個層,以便在低精度下具有更多層。之後,大多數層使用低精度範圍內的量化輸入張量,並且可以在低精度下進行推斷。
目前,OpenVINO 推斷引擎支援以下層以 INT8 低精度計算模式
- 卷積
- 全連線
- ReLU
- ReLU6
- 重塑
- 置換
- 池化
- 壓縮
- 逐元素
- 連線
- 重取樣
- MVN
在網路中連續儲存的此類層越多(並且可以針對 INT8 推斷進行融合),預期的效能提升就越大。
POT 中實現了兩種主要且推薦使用的量化演算法
- **DefaultQuantization** - 用於獲取 8 位量化快速且在大多數情況下準確結果的預設方法。
- **AccuracyAwareQuantization** 允許在量化後保持在預定義的精度下降範圍內,以提高效能。精度檢查器工具是 OpenVINO 工具包的一部分,用於使用帶註釋的資料集驗證量化過程中的模型精度。
接下來,我們將重點介紹 DefaultQuantization 演算法,即使使用未帶註釋的資料集,我們也可以使用它來執行 INT8 模型量化。



3.3 模型量化
首先,我們需要準備一個將在量化過程中用作輸入資料的資料集。從官方 網站 下載對齊的 LFW 資料集,並將所有影像放到單個資料夾中
mkdir -p ~/openvino_optimization/data cd ~/openvino_optimization wget http://vis-www.cs.umass.edu/lfw/lfw-deepfunneled.tgz tar -xzf lfw-deepfunneled.tgz cp ./lfw-deepfunneled/*/*.jpg ./data/. cd ~/openvino_optimization/models
其次,為 POT 準備一個包含量化引數的配置檔案。讓我們使用預設模板,使用我們模型的資訊更新它,並儲存為 quantization_spec.json
{
/* Model parameters */
"model": {
"model_name": "blazeface_fp32_int8", // Model name
"model": "blazeface_fp32.xml", // Path to model (.xml format)
"weights": "blazeface_fp32.bin" // Path to weights (.bin format)
},
/* Parameters of the engine used for model inference */
"engine": {
/* Simplified mode */
"type": "simplified",
"data_source": "../data"
},
/* Optimization hyperparameters */
"compression": {
"target_device": "CPU",
"algorithms": [
{
"name": "DefaultQuantization",
"params": {
"preset": "performance",
"stat_subset_size": 300,
"shuffle_data": false
}
}
]
}
}
最後,執行模型量化。生成的模型將儲存在 ./optimized 資料夾中
pot -c quantization_spec.json --output-dir . -d
對於第二個模型(FaceMesh),我們只需要更改模型名稱和配置檔案中的路徑,然後重複相同的命令。
我們可以看到,量化後的模型大小與全精度浮點模型相比大幅減小:對於 BlazeFace 為 404kB -> 130kB,對於 FaceMesh 為 2.4MB -> 663kB。
4. 基準測試工具
OpenVINO 工具套件提供了另一種工具——基準測試應用程式,可用於在目標裝置上進行快速推理和效能測量。該工具有兩種版本:C++ 和 Python。與之前工具一樣,我們將繼續使用 Python 環境。
4.1 安裝和配置
在開始使用基準測試工具之前,我們需要安裝 Python 依賴項。
cd <OPENVINO_INSTALL_DIR>/deployment_tools/tools/benchmark_tool/ pip install -r requirements.txt
4.2 執行模型推理
在最簡單的情況下,我們只需指定要測量的模型和所需的目標裝置即可執行該工具。
python benchmark_app.py -m ~/openvino_optimization/models/blazeface_fp32.xml -d CPU
命令輸出將包含所有執行步驟的日誌,最後一步將包含效能測量日誌。
Count: 7292 iterations Duration: 60055.49 ms Latency: 32.82 ms Throughput: 121.42 FPS
4.3 比較模型效能
正如 所述,為了實現 OpenVINO INT8 量化的優勢,我們應該使用至少包含一個 x86 指令集擴充套件的英特爾硬體:AVX-512、AVX2 或 SSE4.2。在此示例中,以下結果使用的是配備 SSE4.2 指令集的英特爾酷睿 i5-3570K CPU。
讓我們比較一下我們轉換後的模型的測量結果。
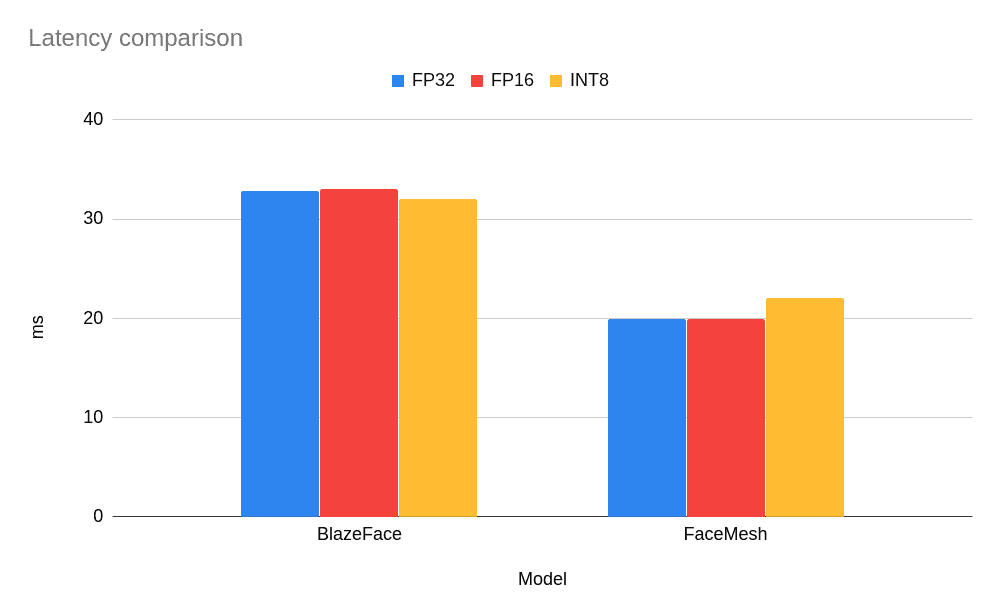
如您所見,對於如此小的模型,沒有觀察到效能提升,而對於 FaceMesh 模型,低精度 INT8 模型導致延遲略有增加(即,它執行任務的速度更慢)。但是,對於更經典且更大的網路而言,情況如何呢?尤其是那些經過低精度推理驗證並在 OpenVINO 開放模型庫 中部署的網路?讓我們從模型庫中獲取一個準備好的模型,並比較基準測試結果。以下是基於 MobileNet 主幹的 face-detection-adas-0001 模型的結果。
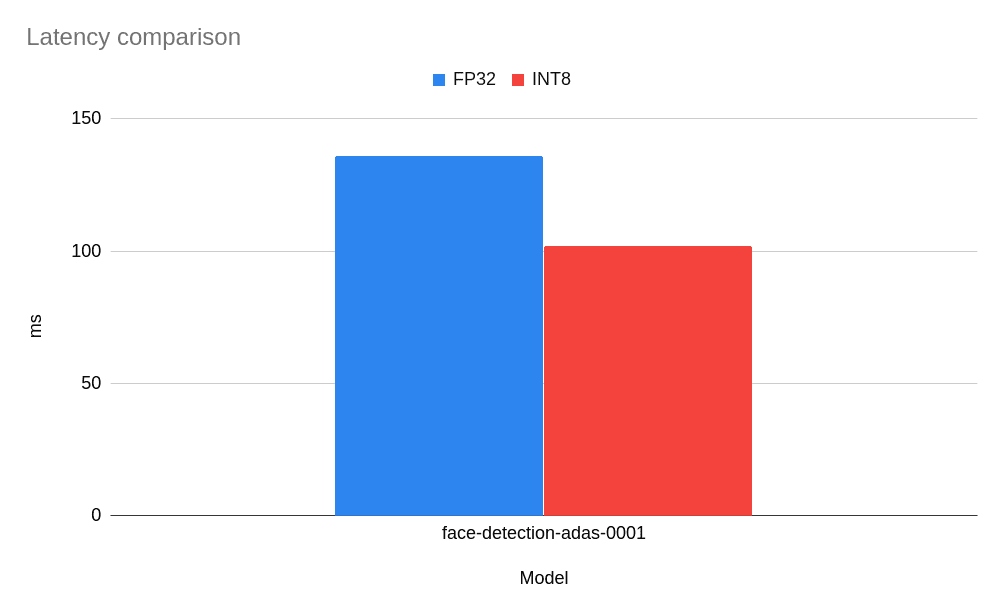
好吧,對於這個模型,我們可以觀察到大約 25% 的效能提升。這是一個不錯的結果,我們擁有一個提供更快推理的小型模型。
有關英特爾軟體產品中效能和最佳化選擇的更多資訊,請參閱 https://software.intel.com/articles/optimization-notice。
4.4 比較模型精度
保持足夠的精度非常重要,這樣應用程式才能繼續滿足功能要求。讓我們從之前的 文章 中獲取 OpenVINO 推理管道,看看我們能夠實現哪些最佳化。我們需要用轉換為 FP16 和 INT8 格式的模型替換原始模型。
從視覺上看,FP32 和 FP16 模型具有相同的質量,但 INT8 模型通常會提供明顯更差的結果。
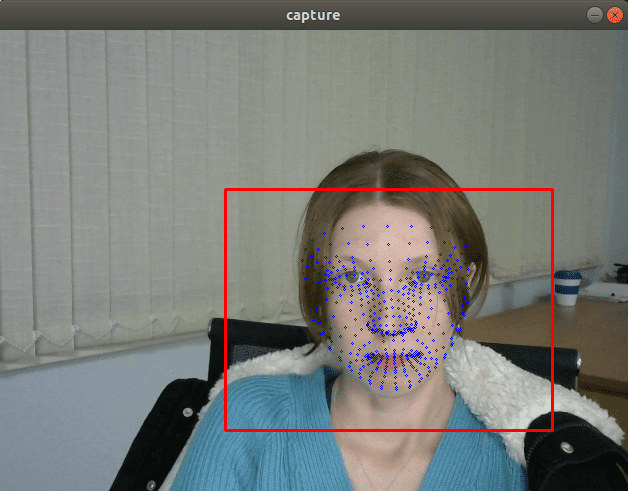
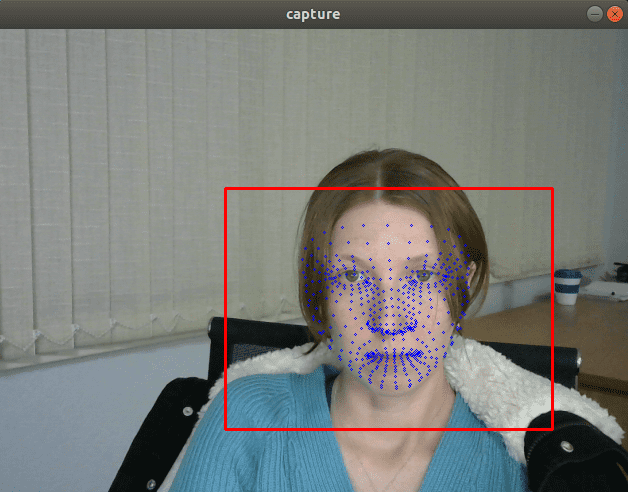
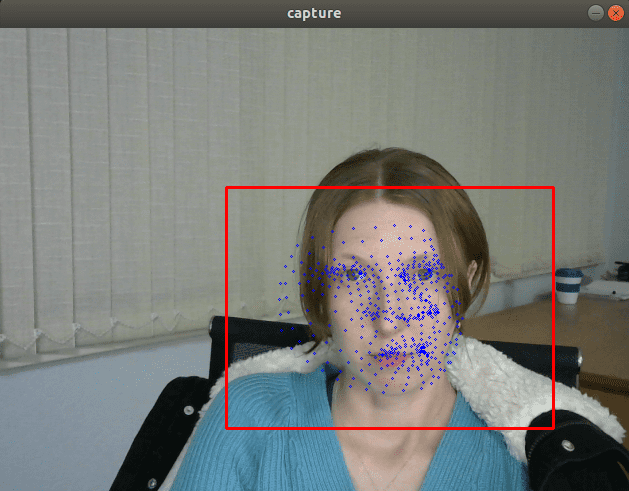
如果我們插入一個列印模型輸出的除錯跟蹤,我們會發現 FP32 和 FP16 模型返回的值幾乎相同,但 INT8 模型返回的值可能會因量化誤差而相差 10% 以上。
我認為結果在一定程度上是可以預期的,因為我們只是使用了簡單的預設量化版本,該版本並非旨在最大程度地提高精度。為了提高 INT8 模型壓縮中的精度,我們需要使用 AccuracyAwareQuantization 演算法。它需要我們準備一個帶註釋的資料集,執行量化並檢查精度。我將把這種型別的量化排除在本篇文章的範圍之外。
5. 總結和結論
我們探討了 OpenVINO 工具套件中的一些最佳化 DNN 模型推理執行速度的功能。這些工具允許您在效能和精度之間取得平衡,這些平衡對於您的應用程式至關重要。當然,加速通常會轉化為節省成本,並且通常是許多即時互動式應用程式的重要要求。
測試日期:2020 年 9 月 22 日
完整系統配置詳細資訊:Oracle VM VirtualBox、Ubuntu 18.04.5、英特爾酷睿 i5-3570K CPU @ 3.40GHz × 4
設定詳細資訊:OpenVINO 工具套件版本 2020.4
測試人員:Alexey Perminov,OpenCV.AI
貢獻——如果您有任何改進產品的方法,我們歡迎您為開源的 OpenVINO™ 工具套件做出貢獻。
想了解更多?加入英特爾社群論壇的討論,討論深度學習和 OpenVINO™ 工具套件的一切。
英特爾致力於尊重人權,並避免參與侵犯人權的行為。請參閱英特爾的 全球人權原則。英特爾的產品和軟體僅供使用於不會造成或促成侵犯國際公認人權行為的應用程式。
英特爾、英特爾標識和其他英特爾商標是英特爾公司或其子公司的商標。
OpenCV 內容合作關係
本文由 OpenCV 團隊的一名成員為英特爾撰寫,作為 OpenCV 內容合作關係計劃的一部分。該計劃允許公司贊助與 OpenCV 使用者相關的文章。這些文章將與我們的時事通訊訂閱者和社交媒體訂閱者共享。


