
簡介
近年來,人工智慧領域發展迅速。透過利用人工智慧技術,機器可以完成大量任務,從為您的照片應用快照濾鏡到自動駕駛汽車。與人工智慧經常互換使用的另外兩個術語是機器學習和深度學習。什麼是機器學習和深度學習?它們的意思相同嗎?或者它們彼此完全不同?還是它們之間存在聯絡?
這篇全面而有趣的文章將重新闡述這些問題,同時探討深度學習與機器學習。
什麼是機器學習?
在我們解決機器學習與深度學習的古老問題之前,讓我們簡要了解一下它們的定義。
機器學習(ML)是人工智慧的一個子領域,圍繞著利用資料開發計算機演算法。它們透過分析和從資料中推斷來幫助機器做出決策或預測。
就像人類透過理解輸入來獲取知識一樣,機器學習旨在從輸入資料中做出決策。機器學習的強大引擎是演算法。
根據資料的結構和數量,可以使用不同的機器學習演算法。
什麼是深度學習?
深度學習是機器學習的一個子領域,它利用神經網路來模擬人腦在機器上的工作方式。神經元在神經網路中根據大量資料的訓練進行配置。就像演算法是機器學習的強大引擎一樣,深度學習擁有模型。這些模型從多個數據源獲取資訊,並即時分析這些資料。
深度學習模型包含構成神經網路中層的節點。資訊透過每一層傳遞,試圖理解資訊並識別模式。
深度學習模型可以從難以理解的資料集中建立更簡單、更高效的類別,因為它可以識別高階和低階資訊。
在它們進行正面交鋒之前,讓我們看一下最常用的機器學習演算法。
最常見的機器學習演算法
演算法是機器學習的基礎,資料科學家和大資料工程師可以利用它對資料進行分類、預測和獲取見解。
在本節中,我們將討論一些最常用的機器學習演算法。
線性迴歸
它是一種用於資料科學和機器學習的演算法,它提供了一個因變數和自變數之間的線性關係,以預測未來事件的結果。
雖然因變數會隨著自變數的變化而變化,但自變數在其他變數發生變化時保持不變。模型預測正在分析的因變數的值。
線性迴歸模擬變數之間的數學關係,並對數值變數或連續變數進行預測,例如價格、銷量或薪資。
為什麼要使用線性迴歸演算法?
- 它可以有效地處理大型資料集。
- 它可以作為複雜 ML 演算法比較的良好基礎模型。
- 易於理解和實現。
憑藉其易用性和效率,線性迴歸是一種基本的機器學習演算法,每個人都應該掌握。
邏輯迴歸
如果一個數據集有很多特徵,我們該如何對它們進行分類?這就是邏輯迴歸發揮作用的地方。邏輯迴歸是一種監督學習的形式,可以根據一些自變數預測某些類別的機率。簡單來說,它分析變數之間的關係。因為它預測離散值的輸出,所以它給出一個介於 0 和 1 之間的機率值。與用於解決迴歸問題的線性迴歸不同,邏輯迴歸解決的是分類問題。
為什麼要使用邏輯迴歸演算法?
- 與其他演算法相比,它更容易實現、解釋和訓練。
- 它透過衡量變數的相關性提供有價值的見解。
- 適用於線性可分資料集。
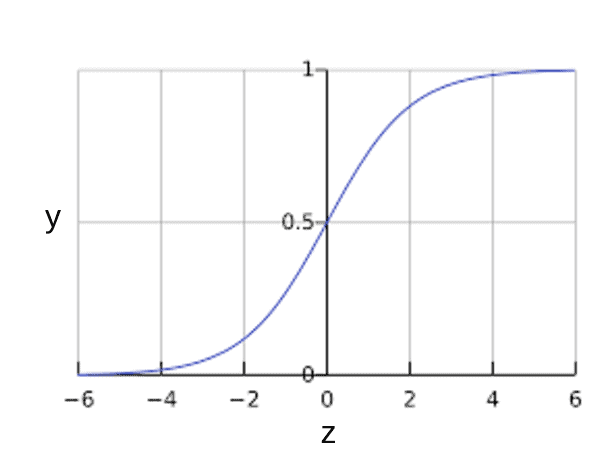
邏輯迴歸
邏輯迴歸是另一種常用的機器學習演算法,它利用機率來預測結果,並且是資料科學家和資料分析師必須掌握的演算法。
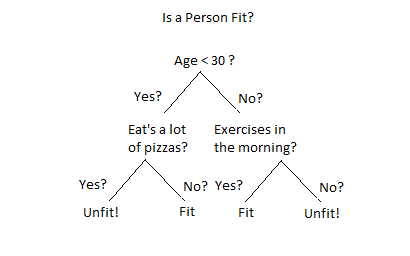
決策樹
這是另一種監督學習的形式,其中資料根據不同的條件進行拆分。根屬性的值與實際資料集中記錄的屬性進行比較。這在根節點中完成,並沿著分支向下到下一個節點。每個連續節點的屬性值與子節點進行比較,直到到達樹的最終葉子節點。
與前兩者不同,決策樹可用於分類和迴歸任務。
決策樹包含
- 決策節點:資料在此處拆分。
- 葉子:最終結果在此處產生。
為什麼要使用決策樹演算法?
- 它可以處理多輸出問題。
- 它可以處理分類資料和數值資料。
- 它易於進行資料預處理,使其操作起來不那麼繁瑣。
- 它不需要資料縮放。
- 它不受資料中缺失值的影響。



決策樹是另一種重要的機器學習演算法,常用於分類和迴歸問題。
支援向量機
支援向量機(也稱為 SVM)是一種用於迴歸和分類問題的監督機器學習演算法。SVM 最初在 60 年代被提出,主要用於解決分類問題。它們最近獲得了普及,因為它們可以處理連續變數和分類變數。
主要地,它們用於透過識別超平面來分離不同類的數點。它們的選擇方式是最大化超平面與每個類中最接近的資料點之間的距離。這些接近的資料點稱為支援向量。
支援向量機是複雜的 ML 演算法,可以執行迴歸和分類任務,並且可以透過核心處理線性資料和非線性資料。
降維演算法
在機器學習中,可能存在過多的變數需要處理。這可能以迴歸和分類任務的形式出現,稱為特徵。降維涉及減少資料集中特徵的數量。這是透過將資料從高維特徵空間轉換為低維特徵空間來完成的,同時確保在轉換過程中資料中存在的有意義的屬性不會丟失。
由於資料量減少,降維訓練效果更好,並且需要更少的計算時間。
為什麼要使用降維演算法?
- 它透過減少特徵來幫助資料壓縮。
- 較少的維度意味著較少的計算量,並且演算法訓練速度更快。
- 它消除了不必要的、冗餘的特徵和噪聲。
- 使用較少的資料,模型精度會大幅提高。
處理大量特徵可能是一項艱鉅的任務。但是,透過降維等 ML 演算法方法,我們可以利用如何使用它們的力量,甚至去除冗餘的特徵。
K 近鄰
K 近鄰演算法(也稱為 KNN)是一種監督機器學習演算法,它使用非引數 ML 原則執行分類和迴歸任務。KNN 基於類似資料點具有類似標籤或值的理念。k 是用於分類的標記點的數量,其中 k 指的是用於確定結果的標記點的數量。
在訓練過程中,這種 ML 演算法將整個訓練資料集儲存為參考。計算所有輸入資料點與訓練示例之間的距離以進行預測。

該演算法根據 k 個鄰居與輸入資料點之間的距離來識別 kNN。因此,對於分類任務,將 kNN 中最常見的類標籤分配為輸入資料點的預測標籤,並計算 kNN 的目標值的平均值以確定輸入資料點的值。
為什麼要使用 K 近鄰?
- 它的實現不需要複雜的數學公式或最佳化技術。
- 分析資料時不做出任何關於其分佈或結構的假設。
- 只有一個超引數 k,使其易於調整。
- 不需要訓練,因為所有工作都在預測過程中完成。
kNN 是一種惰性學習演算法,它在執行時進行預測,而不是基於學習模型的預測。
深度學習模型如何超越 ML?
深度學習模型能夠在各種任務中勝過機器學習演算法,這是因為它們能夠直接從資料中建模複雜的模式和關係,而無需手動設計特徵。讓我們探討深度學習如何在許多領域中表現出色。
自動特徵提取
深度學習演算法能夠自動識別特徵,而不是像傳統機器學習模型那樣使用人工設計的特徵。這種能力在影像識別和語音識別等領域特別有用,因為在這些領域手動設計有效的特徵極其困難。
分層特徵學習
深度學習模型透過學習多層表示來構建資料的層次化表示。這使得模型能夠有效地捕捉簡單和複雜的模式。
處理高維資料
與傳統機器學習模型不同,深度學習模型在高維資料(如影像、影片和文字)上表現出色,而傳統模型在處理高維資料時可能會遇到困難。例如,影像中的單個畫素值可能包含數萬甚至數百萬個值。
可擴充套件性和效能
深度學習模型隨著資料量的增加而效能提升,而傳統機器學習演算法在資料量增加時往往會達到平臺期甚至效能下降。這種可擴充套件性在大型應用中至關重要,例如在大資料環境中遇到的應用。
靈活性和適應性
深度學習模型只需對架構進行少量調整,即可適應各種任務。在影像分類、目標檢測甚至影片分析中,都可以輕鬆使用相同的卷積神經網路(CNN)架構。
端到端學習
深度學習的優勢包括端到端學習,它允許模型直接從原始資料訓練到輸出結果,減少了需要領域專業知識的中間步驟。這在輸入資料和輸出之間關係不明確的複雜任務中是一個顯著的優勢。
最先進的結果
許多領域都受益於深度學習,它超越了傳統的機器學習模型甚至人類專家,例如玩圍棋等複雜遊戲以及基於影像診斷醫療狀況。
儘管深度學習模型功能強大,但它們也存在一些缺點,例如需要大量標記資料、計算複雜度以及缺乏透明度(即缺乏資料透明度,“黑盒”)。因此,深度學習和傳統機器學習之間的選擇取決於手頭任務的具體要求和約束。
深度學習與機器學習:對決
我們終於到達了本文的核心。我們之前已經看到深度學習模型在某些方面優於機器學習演算法。在本節中,我們將討論區分因素,比較它們的效能,並考察一些現實世界的應用。
| 區分因素 | 機器學習 | 深度學習 |
| 定義 | ML是人工智慧的一個子領域,它透過利用歷史資料,基於統計模型和演算法進行預測和決策。 | DL是ML的一個子領域,它試圖透過建立可以做出智慧決策的人工神經網路來複制人腦的工作原理。 |
| 架構 | ML基於傳統的統計模型。 | DL使用具有多層節點的人工神經網路。 |
| 學習過程 | 1. 透過使用者查詢獲取新資訊 2. 分析資料 3. 識別模式 4. 進行預測 5. 將答案發送回使用者 | 1. 獲取資料 2. 資料預處理 3. 接下來是資料分割和平衡 4. 模型構建和訓練 5. 效能評估 6. 超引數訓練 7. 模型部署 |
| 計算和資料需求 | 1. 獲取資料 2. 資料預處理 3. 接下來是資料分割和平衡 4. 模型構建和訓練 5. 效能評估 6. 超引數訓練 7. 模型部署 | 1. DL可以處理非結構化資料,如影像、文字或音訊。 2. 由於其複雜性,它需要高計算能力。 3. DL需要大量資料進行訓練。 |
| 特徵工程 | ML要求工程師識別應用的特徵,然後根據領域和資料型別進行手工編碼。 | DL透過從資料中學習高階特徵,減少了為每個問題開發新的特徵提取器的工作量。 |
| 型別 | ML可以廣泛分類為 1. 監督學習 2. 無監督學習 3. 強化學習 | DL具有以下模型 1. 卷積神經網路 2. 迴圈神經網路 3. 多層感知器 |
| 處理技術 | ML使用各種技術,如資料處理或影像處理。 | DL依賴於構成多層的神經網路。 |
| 問題解決方法 | 在ML中,問題被分解成多個部分並分別解決,然後將這些部分組合起來得到最終結果。 | 使用DL,我們可以端到端地解決問題。 |
| 缺點 | ML的一些缺陷包括 1. 演算法開發需要高水平的技術知識和技能。 2. 一些ML演算法難以解釋,難以理解預測是如何做出的。 3. ML演算法需要大量資料進行有效訓練。 4. 如果使用有偏差的資料進行訓練,則模型也可能存在偏差。 | DL的一些缺陷包括 1. DL模型需要高計算資源,如良好的記憶體和強大的GPU。 2. 由於模型依賴於資料質量,如果資料不完整或存在噪聲,效能可能會受到負面影響。 3. 由於DL模型在大量資料上進行訓練,因此資料隱私和安全問題始終存在較高風險。 |
| 效能比較 | 1. ML通常在解決簡單問題時表現良好。 2. ML演算法隨著從資料中學習而提高準確性。 3. 它們具有高度可擴充套件性,能夠處理大型資料集。 4. 與DL相比,ML不需要那麼多的計算能力,並且更容易設定和分析。 5. ML需要仔細選擇特徵並調整引數以獲得最佳效能。 6. ML演算法需要人工干預進行特徵提取。 | 1. DL擅長解決複雜問題。 2. DL可以實現高準確率,用於複雜任務,如自然語言處理或機器人技術。 3. 使用並行處理硬體,DL可以縮短訓練時間。 4. 雖然DL需要高計算資源,但隨著資料量的增加,其效能會更好。 5. 它需要調整許多引數,但一旦網路架構確定,它就可以從原始資料中自行學習。 6. 與ML不同,DL模型不需要人工干預進行特徵提取。 |
| 職業機會 | 使用ML,可以從事以下角色 1. 機器學習工程師 2. 資料科學家 3. 資料分析師 4. 商業智慧分析師 需要具備以下專業知識 1. 統計分析 2. 監督和無監督學習演算法知識 3. 特徵工程 4. 資料預處理 | 使用DL,可以從事以下角色 1. 深度學習工程師 2. AI研究科學家 3. 計算機視覺工程師 4. 機器人工程師 5. 解決方案架構師 需要具備以下專業知識 1. 神經網路 2. 深度學習框架 3. 模型最佳化技術 4. 強化學習 |
結論
本文到此結束。我們研究了機器學習和深度學習的定義,回顧了常見的機器學習演算法,最後比較了深度學習與機器學習,以及一些關鍵的區別因素。
請繼續關注;我們將在人工智慧、深度學習和計算機視覺方面釋出更多有趣且全面的文章。
下次再見!


